阿拉帮侬
Voice-Based Urban AI Agent for Shanghainese-Speaking Older Adults
Year:
Fall 2026 (Specialization Team Project, Cornell Tech)
Role:
ASR & Data Pipeline Lead · Co-Lead (pair project with Haoyang Song)
Stack:
Python · PyTorch · Whisper · Qwen3-ASR · LoRA · Hugging Face · LLM Function Calling · Map / Service APIs
Type:
Dialect ASR · LLM Agent · Urban Accessibility · Research
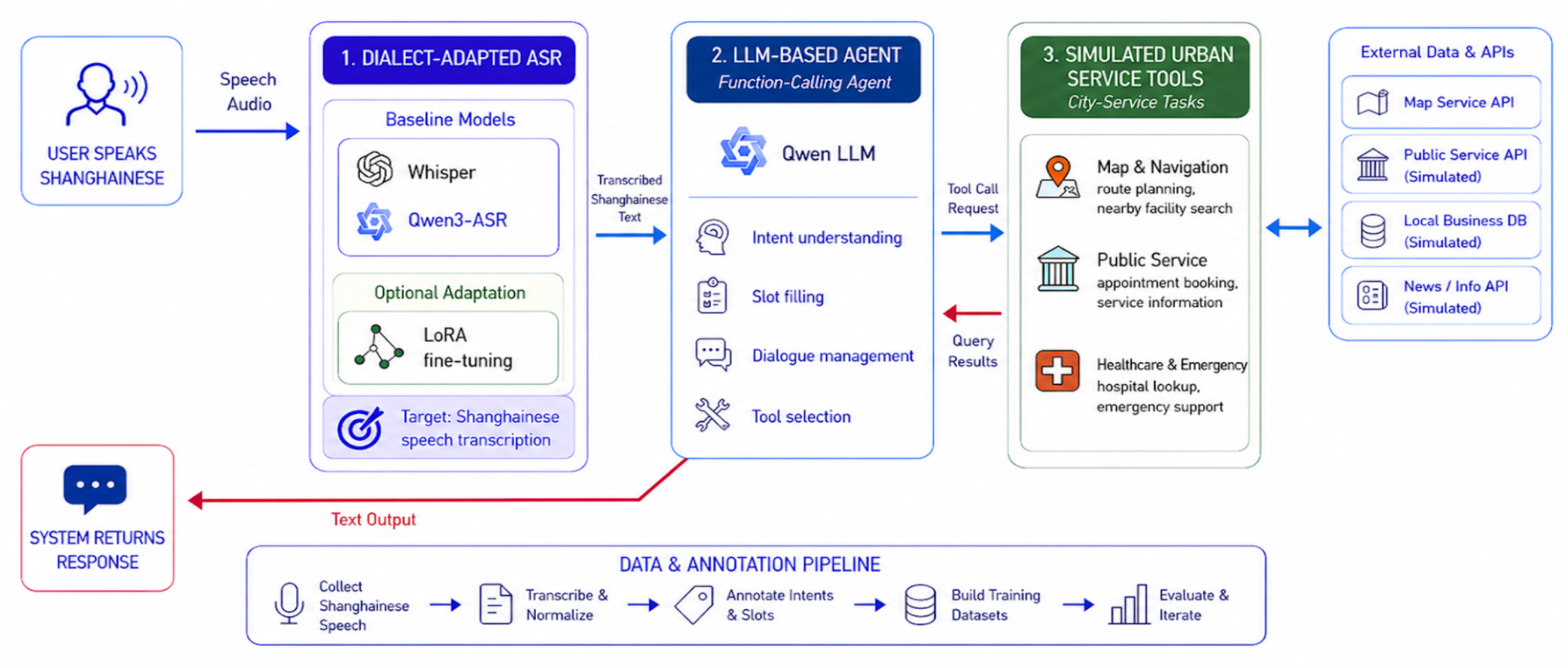
ASR → LLM Agent → Tools — a voice-first interface for digital city services in Shanghainese
阿拉帮侬 (Wu/Shanghainese for "we help you") is a voice-based urban AI agent that helps Shanghainese-speaking residents — especially older adults — access digitized public services through speech rather than Mandarin-based or text-based interfaces.
As cities like Shanghai push more services into mobile apps and web portals, longtime residents who are most comfortable in Shanghainese (a variety of Wu Chinese) are systematically pushed out of those flows. This project exists to close that gap.
This is a Cornell Tech 8-credit Specialization Team Project (pair project with Haoyang Song). I lead the ASR & data-pipeline track — dataset construction, baseline ASR evaluation on Shanghainese, LoRA-based dialect adaptation, and the LRC-style annotation pipeline. Haoyang leads the LLM agent and tool/system integration. We co-design the system architecture, evaluation protocol, and end-to-end error analysis.
Final prototype is targeted for December 6, with deliverables including a dialect-adapted ASR model, an LLM agent with function calling, and a small set of simulated urban service tools.
Research Questions
① ASR on Shanghainese
How accurate are existing and fine-tuned ASR models — Whisper, Qwen3-ASR, and LoRA-adapted variants
— at transcribing Shanghainese speech?
② Agent Reasoning
How well does an LLM-based agent perform on intent recognition and tool calling for city-service
tasks, given dialect-transcribed input?
③ Error Patterns
What are the dominant failure modes in a Shanghainese-based interactive system — phonetic ASR
errors, intent ambiguity, or tool misinvocation?
System Architecture
The system is a three-stage pipeline. Each stage is independently evaluable, which is what makes the end-to-end error analysis tractable:
🎙️ Dialect-Adapted ASR
Whisper / Qwen3-ASR baselines + LoRA fine-tuning on Shanghainese data. Outputs dialect transcripts
plus optional word-level timestamps for downstream alignment and error analysis.
🧠 LLM Agent (Function Calling)
Reads transcripts, infers user intent, and routes to the right tool with the right arguments.
Designed around modern function-calling APIs so the agent can fail gracefully and re-prompt.
🛠️ Simulated Urban Service Tools
Appointment booking, information retrieval, route planning, hospital lookup, and emergency
assistance — all wired through map and service APIs as callable tools.
ASR & Data Pipeline — My Track
Baseline Evaluation
Benchmarking Whisper and Qwen3-ASR on Shanghainese speech to quantify how far off-the-shelf models
fall — measured with WER/CER against transcribed Shanghainese audio.
LoRA Dialect Fine-tuning
Parameter-efficient fine-tuning on a small set of manually corrected Shanghainese data — keeps the
fine-tune feasible under low-resource constraints while targeting dialect-specific phonetic shifts.
Annotation Pipeline (Fallback)
If public data falls short, build an LRC-based recognition + manual correction pipeline that turns
public Shanghainese audio (recordings, online video) into transcribed training/evaluation data.
Datasets in Use
ShUD (Shanghainese Universal Dependency Treebank) for linguistic structure, MDT-AE066 /
Shanghai Dialect Conversational Speech Corpus for ASR evaluation, and WenetSpeech as a
Mandarin baseline for comparison.
Candidate Data Resources
📚 ShUD
Shanghainese Universal Dependency Treebank. 983 sentences / 8,584 tokens — used for
Shanghainese grammar, segmentation, and sentence-structure analysis.
🎧 MDT-AE066
Shanghai Dialect Conversational Speech Corpus. Open-source release: 4.19h transcribed audio
from 10 speaker pairs; reaching out to the provider about a larger 42h variant.
🌐 WenetSpeech
Large-scale Mandarin ASR corpus (22,400h+, 10,000h+ labeled). Used as the Mandarin baseline that
Shanghainese ASR performance is compared against.
Evaluation Plan
ASR Quality
WER and CER on Shanghainese transcripts — comparing pretrained baselines (Whisper,
Qwen3-ASR) against LoRA fine-tuned variants.
Agent Task Performance
Task Success Rate (TSR), Intent Classification Accuracy, and Tool Invocation
Accuracy across representative city-service scenarios — route planning, nearby search, hospital
lookup, emergency assistance.
End-to-End & Error Analysis
End-to-End Task Completion Rate and latency for the full speech → intent
→ tool→ result loop, plus categorized error analysis: ASR phonetic / homophone errors,
intent ambiguity, and tool execution failures.